AI 能写代码,为什么不能"维护系统"
目录
从去年年底开始,Harness 实践已经在所有程序员和厂商内部执行大半年了,现在大家逐渐回过味来:AI 编程也就这样, Harness 自动化确实在一些非常简单的事情上可以,但在绝大部分的日常工作中还是不行。
一个典型的现象是, AI 明明知道架构原则,或者我们已经把足够的架构知识、状态管理规范或模块的边界给到了 agent ,甚至还有 review agent 的角色,但项目还是会越来越乱。同一个变量会出现在十几个地方,相同语义会被重复建模,抽象不被遵守,虽然在同一个项目中,同一个模型会在多次迭代中应用多种 pattern ,把逻辑加的到处都是。
然而如果我们拆开来看每一次 agent 的执行,或让他做自我分析,它每次都能分析的头头是道,代码写的也看起来有这么回事,但就是只是局部上都合理,放全局就相当混乱。
一开始我以为这是 prompt 不够好,或者是 context window 不够大。但随着实践我开始在流程中增加:review agent、architecture rule、memory system,或者定期的反思或多 agent 的讨论。这些设施越加越多,一开始还能稳定住状态,把我发现的反模式问题发现并解决,但一旦继续自我迭代,这套机制也腐化的相当快,马上结构本身就失控了。
本文我就想仔细探讨一下,到底 harness 工程这样一种全自动化开发,问题到底在哪,我们是否能从理论上证明这是一条可行的路径,还是又一次软件工程的迷梦。
传统软件工程对架构一致性的追求
传统软件工程总是追求软件架构的一致性,这是对架构可维护性的要求所带来的。从根本上来说,正是因为需求的快速变化,必须在架构设计上有足够的统一性和灵活性,让软件秩序能维持其自身,不至于过快的落入维护工作量地狱。
这种架构一致性的想法正是工程师们被一次次的需求快速堆积和变化,交付进度的催促,线上事故和客户投诉之中拷打出来的。当他们在实现新功能的时候,心中不由的泛起被各种屎山代码和历史包袱折磨的痛苦,从而非常抗拒不恰当的抽象,不能复用的基类,不可维护的状态管理模型,或者对深依赖树的不信任。一想到今天写的代码在3个月后还要维护,工程师们不得不提起十二分精神对待其代码质量。
良好架构的统一性对人类工程师来说是最自然最舒服的思考模式,也是他们应对需求压力的习惯,更是一种职业美德。
传统软件工程之所以能维持架构,不是因为工程师更理性,这是人类工程师被长期后果训练过,对未来复杂性的痛觉,这是一种来自“时间性”(temporality)的思考模式和感知结果。
LLM 能编程,但做不好工程
AI 当然会写代码,而且写的比我们绝大部分人都好。然而这种好是来自他对大量代码的“背诵”。
我小时候参加 OI ,同学之间相互比赛谁背标程背的快,比赛的时候不管三七二十一,先背一段平衡树出来,哪怕这是一道动归题,我用平衡树的 nlogn 复杂度也能跑出7个点,或者下一题可能用到呢?我们当时就开玩笑说,编程其实就是文科,看谁背的程序多又快,其实我到现在也多少认为计科是沾点文科的。
但搞 OI 的人出来未必擅长软件工程,因为编程和软件工程是两个维度上的问题,前者是解决一个独立的具体问题,而后者应对的是工程复杂度,处理的是不断快速变化的需求,怎么样让一个软件能在正确接住需求的情况下还能维持自身。
现在的 AI 正处在这样一个时刻,他写代码的能力极强,在给定问题上下文的情况下他能很快的做 pattern matching, local reasoning ,对具体问题的解法可以说会是相当有"合理性" 的。
这种能力是来自 LLM 的设计,在一段上下文中做出 semantic completion ,从语言的合理性上推导对问题推理的合理性,从而解决问题。他天然优化的是: P(next token∣context)
然而如我们前面说的,工程问题是对现实需求的长期规划,是对未来3个月我还要维护的动这个软件的职业压力,是一种来自“后果时间”的痛觉,从而产生的对架构做收缩的冲动。
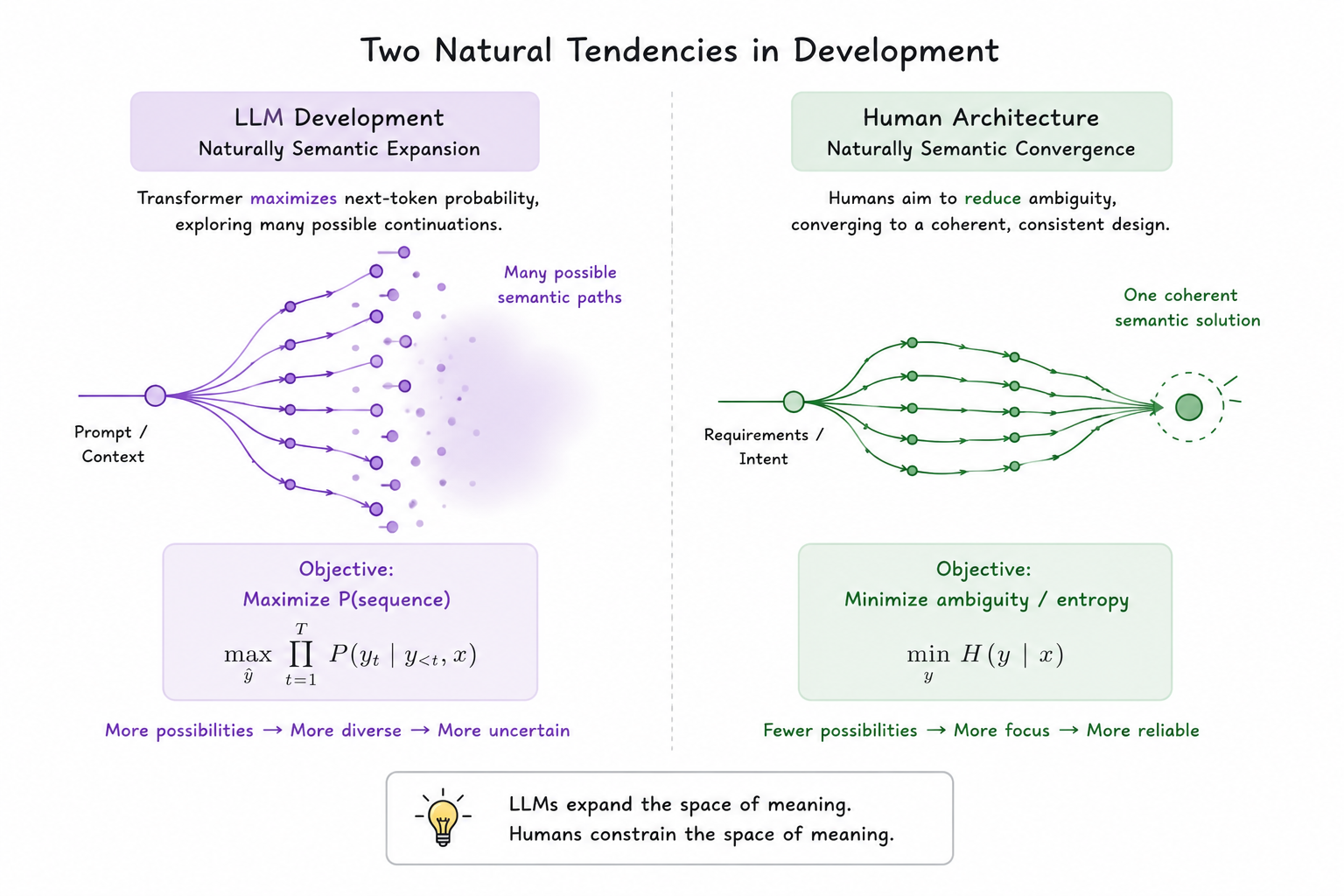
也就是说, LLM 可以很好的解决当前 patch 的合理性,把人类给他的 prompt 接住并完成,一切都是一种合理的处理方式,然而唯独没有对 Long horizon architectural stability 的关注,因为在 LLM 的视野里,他不需要承担未来,不用面对三个月之后的维护灾难,没有人在不断的提醒他,这样写是有隐患的。
用 review / reflection / memory 来做约束可以吗?
单 Agent 有这个问题很正常,人也不可避免,所以聪明的工程师们也都意识到这个问题,给 agent 增加多角色分工、反馈链路和记忆系统。这一套就是我们现在很流行的 harness 工程。
但是值得注意的是,这些结构和角色也大多都是 LLM 所构成的,那就有一个不可避免的问题:语义的漂移。
比如说我现在要做一个 Todo App, 其状态管理的初始设计是这样的:
type Todo = {
completed: boolean
}
我们设定一个架构规则:判断任务是否完成,只能看 completed,不要新增等价字段。
第一次迭代需求是增加“归档”概念,归档后不要显示在列表里。于是 AI 增加归档字段:
type Todo = {
completed: boolean
archived: boolean
}
此时 review 通过,因为 archived 看起来不是“完成状态”,而是“可见性状态”,在语义上是过关的。
接下来我们引入第二个模块 Mobile Sync Layer ,用于把 Todo 同步到 App 上。为了把所有的 Todo 状态能显示到同步状态上, Sync Layer 引入了一个新的枚举:
type Todo = {
completed: boolean
archieved: boolean
status: 'active' | 'completed' | 'archived'
}
这里 review 仍然是通过的,因为这里的 status 的语义目的是用于表示同步的状态位,而不是说明 Todo 是否已经完成,规则没有被打破,但明眼人已经看出来了:现在 status 已经可以完全替代 completed 表示任务状态,只是我们的架构规定中不允许他这么使用。
但接下来一个关于 Mobile Sync 的需求中,任何的关于 Sync 这个任务域中 Todo 状态的标识,AI就完全可以跳出架构约束,比如:
syncModule.getCurrentTodo().status == 'completed'
在语义上完全合法,因为我们的架构约束的是 Todo 这个域的状态判断,没有约束 Sync Module 里如何做状态判断的,架构漂移就发生了,后续 sync module 里的逻辑甚至可以把 archived 的字面量当完成,因为在语法和语义上这也是可能的,于是真正的 bug 也产生了。
我们人类可以一眼看出这里的问题,是因为我们知道 sync module 里的任何 Todo 也都应该是 Todo 域里的实体,然而 LLM 看不出来,因为他只追求语义上的最大概率,而不是架构漂移的最小化,也就是我们希望系统是 minDrift(St,S0) ,但 LLM 的特性是 max 𝑃(𝑀_𝑖∣𝐶_𝑖) 的。
LLM 在单次执行过程中只能保证语义上的概率最大化,这种语义漂移会在多次执行中积累,从而在迭代中不断的重新解释语义,重新压缩抽象,重新组织模式,即使是多角色约束,这种语义的漂移也是存在,而且因为 harness 执行的就是依赖多轮循环的,这样的漂移会累积的更快。
我现在自己的工作流,单个需求需要执行 2000 次 LLM 调用,这中间是有多角色和门禁循环的,涉及需求解释,代码编写,自测和集测,部署验证等多个环节20多个节点。即使我只有0.01%的语义漂移,2000次迭代后纯理论推算有 20% 左右的整体漂移率。
可以说在理性的角度,语言化反思 ≠ 时间化后果。我们在架构设计时需要反复考虑的是如何持续收缩语义,而 LLM 的原理天然的就会在当前上下文中扩展他的语言,这里有一种结构化的矛盾。正如维特根斯坦说的,“规则并不能自我保证执行”,因为每一次新的上下文,都会重新解释规则本身。始终 LLM 还是一种语言游戏,他的理性还是一种符号层模拟。
既然 AI 在理论上会持续 drift,他所维护的架构也会漂移的非常迅速,那我们引入非 LLM 的传统控制器行不行?比如使用 bash 脚本持续监控我们的项目,让代码相互之间完全隔离,某些变量的所有权使用 lint 完全控制?
软件工程的银弹
历史上软件工程多次引入某种形式化的工具,试图简化对软件系统的表达能力,比如 UML 或更偏业务的 BPMN。他们现在也都还活着,但不能算是软件工程的主流,在特定领域中他们还活跃,比如面向运营的 DSL 场景,然而和他们诞生时希望的宏伟目标肯定是相去甚远的。为什么?
这里我们引入 Ashby 必要多样性定律 (W. Ross Ashby), 其核心是 Vcontroller ≥ Vsystem , 也就说控制系统复杂度,必须至少等于被控制系统复杂度。
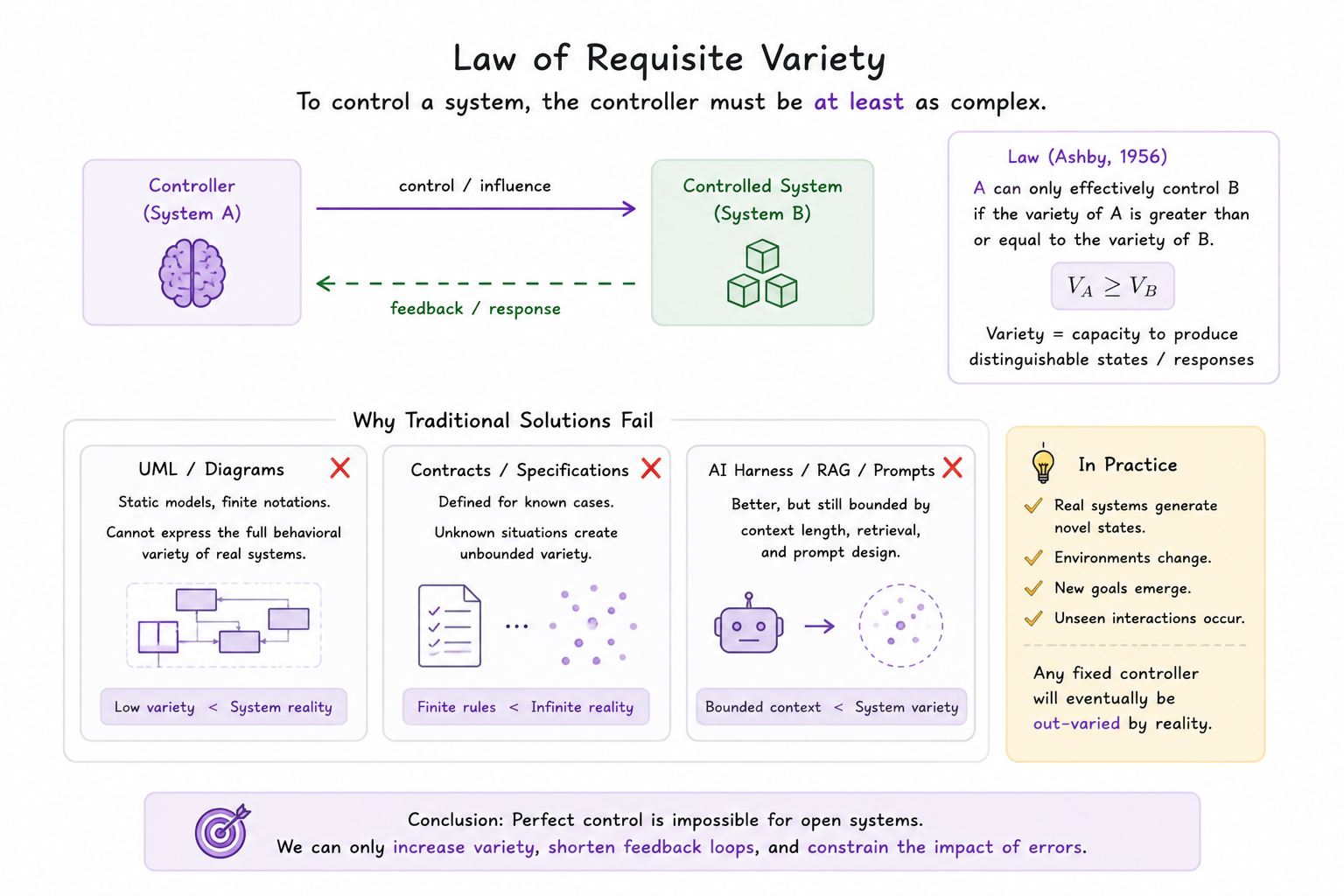
如果我有一个外围的控制系统可以约束一个业务系统的表达能力,让他能按我们规范性的方式去实现业务能力,那么这个控制系统必须能约束业务系统的所有自由度,这个复杂度必然是远高于业务系统的。
也就是说,如果我们的 harness 要能完美约束 LLM 的代码生成能力,他的 spec + 围栏的复杂度一定是复杂于这个 LLM 的代码生成能力,听上去就是不可能的,因为 LLM 所表达的代码能力本身就是图灵完备的。
当然我可以换个思路,我在一个受限的场景中,比如生成的是 DSL ,利用后者的定义与行为约束 + harness 工具链,生成一个完全闭合的应用,理论上是可能的,然而我们是不是再次发明了 UML 、 BPMN 或低代码平台 ?这是否又是软件工程又一次迷梦?
软件工程不存在银弹,AI能解决的是偶然复杂度,而本质复杂度(essential complexity)无法被任何工具消除,需求本身的组合爆炸,状态空间,现实世界规则和业务语义,而且这些会在 AI 时代被放大,因为我们可以完全自由的用 LLM 创造更多的系统、工作流、控制工作流的工作流、对抽象的抽象。
当系统自由度趋近无限时,完全形式化治理几乎不可能。LLM 本质上也是一种高维语义生成系统。如果试图完全约束 AI,最终会回到另一种 DSL / UML 地狱。
也许这次不一样,因为 AI 是可以靠猜的。 AlphaGo 不需要遍历所有可能的走法,靠特征就的概率就能猜出相对最好的棋局可能性。 AI 写代码和 AI 的约束系统也可以猜。不过除了前面说的 LLM 的语义漂移的问题外,本身 AI 的概率模型会有猜错的时候,当因此发生的系统 bug 是否是可接受的呢?
真就无解吗?
向工厂的自动化流水线学习
既然 AI 的代码生成能力是不可靠的,我们需要引入自动化中的控制论来尝试重新建模。
其实我们前面讨论了两种问题:
- 由 LLM 带来的持续的语义漂移,让项目的代码治理状态持续腐化,直到无法控制
- 由必要多样性引入的控制器复杂度会在实际问题中爆炸
所以我们需要考虑:如何控制整个系统的复杂度,同时如何控制在持续迭代过程中的漂移程度。
控制论就是经典的用来把不可靠模块组织成可靠可控制系统的理论。钱学森在上世纪60-70 年代把完全初级阶段的军工体系制造的模块,材料不过关,质量不可靠,工差大的离谱的零件组装成火箭还发上天,就是用的工程控制论,这其中关键的一点就是指标化每一个模块。
工厂的自动化流水线会在每一个子环节中做验证,让这个子环节自我收敛,再交给下一个环节。模块和子流程能收敛靠的就是良好的封装。控制论中对一个子系统的测量,很重要的两个指标叫“过冲”和“阻尼”,其实就是观察一个子系统收敛的速度是过快还是过慢,还是压根就是发散的。
这其实是两个重要的 insights :
- 对于复杂度,我们可以通过模块化和功能化,让复杂度只发生在模块之间的切面上,让每一个模块的功能彻底特化,指标化,可以大幅度缩小我们所需要的控制复杂度
- 我们不需要完全避免漂移,而是让漂移的速度受控,从而让系统是收敛的。这个速度应该比反馈的速度慢,也就是: Tfeedback < Tdrift 让反馈所需的时间小于语义漂移的时间,那么这个系统就是受控收敛的。
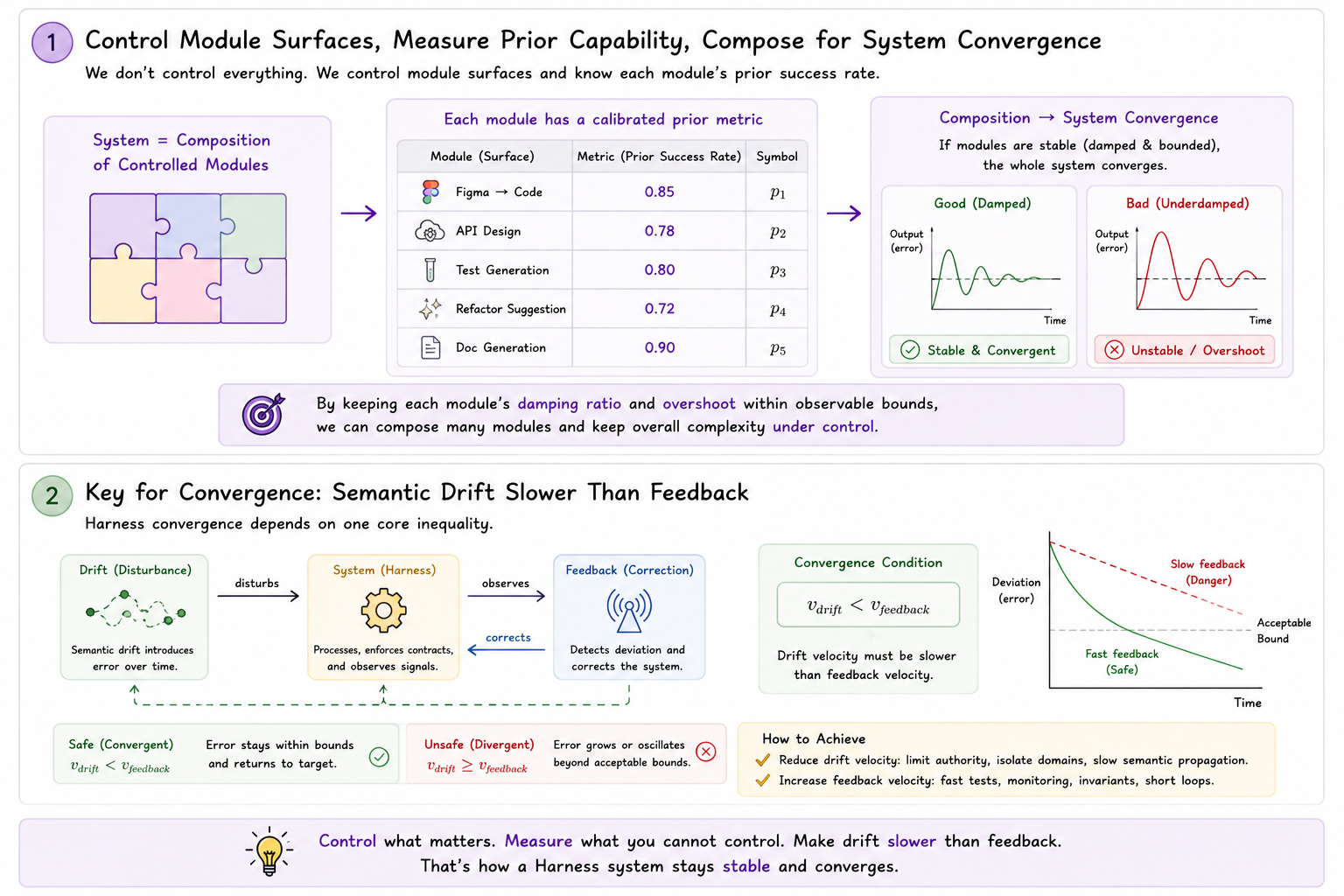
对于第一个复杂度控制的问题我们很好理解,这也是多角色 agent 在 harness 起的很重要的作用,让某一个模块只负责一个单一职能,并对他指标化,我们所需要关注的控制复杂度就能大幅度缩小。比如 ui 模块使用专门的 figma to code 模块,而且他只负责生成标准的无业务逻辑组件,如此我们可以只量化这个模块:额定最大可处理交互数量,额定的交互组合难度和可能性,以及在上述额定可工作范围内的置信成功率,也就是我们提供一个 f2c 的功能不只是一个 mcp ,他本身应该是负责一个可标量的模块,他就有自己的适用范围,在这个范围内他的成功率是置信的,在这个基础上我们可以搭建更大的控制模块。
所有的自动化流水线上的模块都是这样的:工业摄像头需要标定他的视场角,fps, 光圈大小和感光指数,还有色彩还原曲线和工作温度。没有这些指标,自动化工程师们没办法把他们放到自动化环节中。而一旦有了这些指标,即使比工况要求还有距离,我们可以通过增加足够冗余和额外环节来提高通过率。
同时模块化能限制一次 mutation 可见的复杂度切面,这样把复杂度转移到模块内部,能让整个流程变的复杂度可控。
而对于第二个对漂移速度控制的话题,我们需要再展开一下,也就是如何控制系统的漂移速度,让他小于反馈速度,从而能让系统收敛。
自指的符号系统和解释性剩余
我们希望的是在 harness 这条流水线上,每一次输入需求和当前代码,他输出的产物是在语义上收敛到一个完美架构上的,这种完美性表现在语义的一致性,也就是说从输入的需求、代码的历史结构和代码的未来结构上去叙述这个功能,他们呈现出统一性。不论从项目的哪一个出发点去解释这个系统,他的表达都是连贯且一致的,符合所有的输入要求:架构要求、业务需求、安全性要求、可维护性要求、可见性要求、易用性和稳定性、还有性能等。
在一次理想的生产过程中,要达到这样的一致性,我只要让生产的未来状态也被涵盖在控制之中就行了。比如 Todo 列表最大数量从5个变成10个,我的形式化检查认为,只要这个最大数量是一个正整数,且不超过100都是合理的。一个 DSL 系统就是这样构建的。
然而 harness 中无法实现这样的理想生产,是因为他是一个自我指涉的系统,每次输入的需求都会让源码产生新的语义,这些新语义会产生新的诠释和规则,从而改变系统本身的问题域空间。一个能自指的符号系统天然会导致能指的扩展,他就是不收敛的。最麻烦的是,一个 harness 系统本身也是由语义构成的,如果我们要考察 ai 时代的软件工程, harness 也应当是这个软件的一部分,软件本身的问题域在变化时, harness 的问题域也在跟着增长。
这听上去是难题,但其实在人类社会中每天都在发生:社会关系促成新的社会生产力,生产力重塑人的社会关系,新的职业和组织方式诞生,产生新的法律和社会团体,再促进新的生产方式和生产力的诞生。这样的动力在某种社会关系的诞生之初就已经存在,黑格尔意义上的否定-扬弃过程是有本体论地位的。
也就是说,当我们用语义描述一个系统时,这个系统的语义不一致性(否定性)已经存在了,这其实就是一种“解释性剩余”,在传统软件工程中能呈现出的一致性只是因为复杂度不够高或迭代速度不够快导致的一种 "理性假象"的癔症。
当这种不一致性积累到一定程度时,否定性自然就会显现。当 Todo 有许多看起来像完成状态的标志位出现时, completed 是否是唯一状态标志位的语义规则就显得老旧多余。
这里也不是说 harness 可以放弃对语义稳定性的追求,让任意修改都被应用,秩序立即就瓦解,系统马上就退回到不可维护的状态。换句话说,解释性剩余不是要被消灭的 bug,而是系统演化的动力本身;真正的问题是,这个动力能不能被分层吸收,而不是整体扩散。
这里的关键是:不同层次的语义变化对整个系统的语义变化是完全不同的。

Todo 本身的完成状态的语义,和 Todo 在 UI 上是否可展现的语义,重要度是不一样的,前者会影响 Todo 项目在所有子模块中的存在状态,而后者只会影响 Todo 项目在列表页上的可展示性,甚至只是影响他在某个独特 tabbar 上的可展示性而不是全局 UI 。
人类社会也是这样组织的:如果一个社区有居民的垃圾处理共识,社区可以有自己的公约,或业主出钱来优化治理。但整个城市的统一垃圾处理需要市政府收集全体市民意见,形成治理规定,划拨专项资金出台全市都要遵守的政策文件。
影响面大的语义治理速度要慢,影响面小的语义治理速度可以快。这里的快和慢都是相对他们可以如何被反馈感知到所决定的:
- 对于一个限定范围的 UI 呈现修改而言,他的反馈就是自动化的对单模块的 e2e 测试,那么 harness 可以在每次迭代中都低代价的修改他
- 对于一个跨系统的 UI 基础库的变动而言,如果整个系统一周发一次版,他的验证需要在周级别的迭代中才有可能发现不一致性,那么他的修改需要慢的多
- 对于 Todo 的 completed 状态这样核心语义的修改,他需要更长的时间才能发现语义上的漂移,虽然 Todo 确实增加了其他类似状态的属性,但 Todo 的完成状态的语义定义需要月级别的整理,在足够多的其他模块中的对状态表达需求的呈现, AI 总结出一个 boolean 值的状态标记位已经不够,重新提炼新的状态语义形成规则。
可以看到这里我们有两种实践:代码级别的和语义级别的。前者是软件代码本身,而后者代表的是 harness 的知识库。如前面的论述, harness 也应当被看作是软件的一部分,所以这样的分层从传统的软件分层扩展到了 harness 整体的分层。
这是一种延迟反馈的思路 (delayed feedback instability) ,从而让系统的 Tfeedback ≤ Tmutation ,实现收敛。
Harness 时代的多层抽象必须是通过资源垄断的
我们前面提到的语义约束和代码分层,在全功能 AI 面前其实是无力的,AI 可以轻松的语义逃逸:
- Todo 领域模型所在的 core 层不让改, ai 就在 application 层再创建一个 Todo 模型,照样能把需求完成,从此后续的 todo 模型都使用的是 application 层实现的派生
- 通用的基础组件不给增加另一种 button 样式,我直接再在业务层代码中画一个出来,从此其他 button 都继承的这个业务代码里画的 button
由于在核心语义的全面自我 review 之前,这些问题已经发生,再做治理当然可能,但系统的分叉已经是事实。况且这样的全面自我 review 也未必真能发现这些问题,直到线上不一致的事故被投诉上来。
所以 ai 时代的层次抽象一定是对关键资源的垄断,这种垄断不是传统的 lint 或编译器式的检查,而是对核心事实层面的垄断,直接禁止一切可能的逃逸。
Todo模型的核心语义一定是和 Todo 数据表的访问权垄断绑定的。在与 application 层的 harness 交互的切面,他只提供 api 式的访问权限,不会提供任何代码和数据表的访问权,整个系统的校验只围绕 Todo 数据是否被合理的写入读取,就能实现形式化的验证。
UI 的基础组件库则是对渲染层的完全垄断实现的,应用层 harness 不允许创建任何的 html ,所使用的 js 也不允许访问任何的 dom api,只能使用以基础组件库的声明式组合来完成对 UI 的描述。
这里是牺牲灵活性得到的控制力,比如我现在需求就是要增加一个新的实体,比如 calendar ,他和 todo 这个实体之间有很多的关联。现在我的 application 层不允许调整 core 层,怎么实现这样的需求?
如此,就需要有专门的职能团队负责在一个 harness 分层中的横向扩展,并为这种横向扩展的语义稳定性负责。
跨技能工程师和专业职能团队
各公司在引入 harness 实践时都希望能解决工程师的端到端交付能力。传统的技术公司一个很大的难题不是工程师不够多,而是工程师的能力结构不能适应现在的市场需求,现在移动端需求大但我公司的后端人更多,或者有很多数据型的需求但我现在的工程师全是十年的 web dev。裁员和招聘同时发生是不可避免的。
同时跨技能合作会带来沟通成本,一个需求每个人理解的不一样,需要反复沟通,有专门的沟通职能角色,会降低迭代速度。
有了 harness 就好了,只要需求输入的够详细,加上合适的 ai 技能库、知识库和工作流,理论上什么技能的工程师都能创建任意平台的代码功能。
好消息是,确实是这样,各端平台开发的技能 可能 可以通过 ai 来打平,但由此带来的语义分层职能又是一轮新的职业区分化进程。
如我们上面的分析,我们对一个系统的 harness 的多层次结构需要有多个团队来负责,他们的工作变成从原来代码开发,转化为对语义稳定性的管理。当我在这个层引入新的语义,是否还能维持对本层的语义一致性,是否要进行额外的指标化的评估,研究这样的变更带来的下游影响面。其中可能还会有试变动,临时变动和变动效果评估。
就和人类社会对法律法规做调整的过程是一样的,一句话的调整影响很多人的日常生活,需要谨慎研究,也需要专人负责。
这种职能划分无法被传统的技能定义所安排,更多的是工程师对这一问题域的领域知识的理解,同时有能对 harness 模块做工程化标量评估,和组织流程的能力。况且这种职能划分还需要伴随着资源垄断,天然有需要反复协商讨论,甚至争端的可能,其团队化是非常自然的。
也就是说在 harness 时代我们会看到这样一个现象:人人都有端到端交付的技能,但是在同一个业务域上还是有多职能划分的情况,而且这种划分因为资源控制的原因不可调和,最后又形成了多个团队。这个过程中还会产生新的 knowhow ,比如就有把 f2c 模块在当前业务域内调优的专门工程师。
Harness 的未来是现代性的
传统软件开发我们总以为系统应该先完全一致,然后才能运行。但真实世界的大型系统,比如国家、法律、市场、城市从来都是在局部矛盾与持续修补中运行的。
我们软件工程师们需要逐渐对这样一个事实习惯,AI Harness 的持续“漂移”不是 bug,而是开放复杂系统的必然属性,关键是如何让这种漂移受控。
而且这种受控很有可能不是“事实上的”,而是认识论上的范式改变,对系统局部不一致状态的,甚至整体不一致的视而不见,因为他永远存在。比如,我们都很清楚 ai 会有幻觉,会漂移,但只要他的输出切面还是符合约束的,只要先验的成功率组合还没失控,在问题没扩散之前,我们还是认为他是受控的。只有这样,整体的复杂度和可维护性的才有可能。
这可能是我们转向到超大型软件开发的必要妥协,应对服务超复杂需求变化的实际需要而快速扩张的代价,这种动态受控不一致性的认识论转变。
毕竟我们还有这么多疾病要治愈,这么多贫困和饥饿问题要解决,这么多司法公正要裁定,这么遥远的星球要征服,以现在的软件生产效率还是远远不够。