Org Runbook:一组简单的多 Agent 协作 Skills
目录
背景与问题
现在的 AI 实践面临一个重要课题:如何让 AI 在尽量少的提示下,稳定地、长时间地执行复杂任务,并最终收敛到设定目标?
我的实践经验是,上下文工程是最重要的。不论是 subagent、skills,还是 tool call,本质上都是让每个执行环节能够聚焦,并提供充分的可复用外部上下文,从而让执行流程稳定、可控。
举例来说:一次执行一个编码任务,现在的 coding agent 已经能轻松应对。但如果让 coding agent 同时做 review、单测、本地集测、CI、staging 测试、发布等一系列流程,你就需要一份文档来辅助说明——每个环节都有大量细节:环境怎么配置、CI 有什么要求、单测覆盖率要多少、怎样才算 staging 测试完成。
如果用单一文件描述所有过程,AI 会在大量工作中迷失:长时间编码解决 bug 之后忘了进行集测,或者集测发现问题后忘了步骤流程应该回到编码,而是自己直接尝试修复,然后忘了后续步骤。
两种解决方案
此时有两种做法:
方案一:外部脚本控制
用一个外部脚本来控制每个执行环节,每次只做一件事,用脚本把它们串联起来。
方案二:主控 Agent 管理(我的选择)
由一个主控 agent 来管理整个流程。它读的文档只包含流程控制,而具体到子任务时会分离出独立的文档,开启一个 subagent 来执行,并把结果回报给主 agent。这也是一种上下文工程的做法。
比如,编码 agent 只读编码相关的文档:代码规范、目录结构、数据库连接方式、lint 配置在哪里;而测试 agent 只读测试文档:UT 目录在哪里、怎么提错误工单、门禁检查有哪些项目,并强调不允许它改任何代码。所有流程由主控 agent 来完成,由它来决定是推进步骤,还是回到前面的某个步骤。
这个方案的好处是:如果工作流程多变——有些任务是完整端到端的编码过程,有些只是 UI 优化,有些是文档梳理不动代码,有些是研究课题是开放性结果——都可以使用这个流程,而不需要为每种流程都写一个脚本。模糊的语言描述就能让 agent 理解怎么合理组织每个 subagent,编排多样的流程,应对复杂的任务组合。
Org Runbook 工作法
为此,我总结了一套 skill,以 org mode 为核心,让主流程 agent 可以根据任务自己思考并组织一套工作流。在工作流里分配不同角色的 subagent,让他们加载各自的文档或技能,开始独立工作,并更新到 org mode 文件中向主控 agent 汇报进度,再由主控 agent 评估当前执行状态,决定任务的推进方向。我称这套工作方法叫 org runbook 。
为什么选择 Org Mode
Org mode 有几个关键优势:
- 纯文本格式 :方便 Git 管理和 agent 读取
- 自带任务原语 :agent 对它有天然的格式知识
- 丰富的任务操作原语 :
- TODO keyword 表示任务状态
- Subtree & headline 表示任务和子任务的层叠关系
- Task list 可作为独立角色的子任务,也可作为门禁检查的依据
- Logbook 可作为 worklog 记录
- Property drawer 可记录必要属性:分配角色、加载的技能
- Org link 可连接必要文档和输出产物,作为其他 subagent 的参考资料
另外也有大量工具(如 cltpt)可以直接操作和读取这些元素,让大规模任务追踪变得简单。
Skill 套件详解
这套 skills 分成四部分。
Skill 1:runbook-org(基础层)
在每次执行具体任务时被激活,规定每个 subagent 都应遵循一套工作模式:以 org runbook 文件为唯一事实源。
它介绍了如何读取和填写 runbook,让每个 agent 明白执行任务的必要规范:
- 每个任务的 owner、目标、上下文必须齐全,执行者需要提供 findings 和 evidence,并勾选检查点
- Evidence 是第一公民,没有外部链接上 runbook 的不会被认为是事实
- 必须完成规定的检查点,也就是门禁,避免漏步骤
- 禁止删别人的 headline,只专注在自己的工作上
skill 里也规定了一系列可行的操作和禁止的操作,避免 agent 主动改 runbook 里的内容,必须通过受限的动作完成内容改动,避免发生任务处理越界的问题。
*** DONE UI-AUDIT-001: 第一轮 UI/UX 全面审计 :PROPERTIES: :ID: UI-AUDIT-001 :OWNER: worker-1 :STATUS: done :END: - Goal :: 对 Qbot Web 项目进行全面的 UI 质量审计,识别可访问性、性能、主题、响应式设计和 AI 反模式问题 - Context :: - 项目类型:移动端优先的 AI 量化投研 Web 应用 - 技术栈:React + TypeScript + TailwindCSS + antd-mobile - 参考文档:docs/PRDs/PRD1_UI.md - Findings :: - [2026-03-28 10:00] 🔒 开始审计,策略:调用 /audit 技能进行全面审计 - [2026-03-28 10:35] 📋 审计完成:Critical 2, High 5, Medium 8, Low 12 - Evidence :: - [2026-03-28 10:35] file: /home/gsj987/Workspace/Qbot/qbot_web/web/src/pages/Home.tsx # reliability: ★★★ - [2026-03-28 10:35] file: /home/gsj987/Workspace/Qbot/qbot_web/web/src/components/SignalCard.tsx # reliability: ★★★ - [2026-03-28 10:35] file: /home/gsj987/Workspace/Qbot/qbot_web/web/src/components/PositionCard.tsx # reliability: ★★★ - [2026-03-28 10:35] file: /home/gsj987/Workspace/Qbot/qbot_web/web/src/pages/Backtest.tsx # reliability: ★★★ - [2026-03-28 10:35] file: /home/gsj987/Workspace/Qbot/qbot_web/web/src/styles/global.css # reliability: ★★★ - Next Actions :: - [x] 调用 /audit 技能执行全面审计 - [x] 记录所有发现的问题(按严重性分类) - [x] 输出详细的审计报告
这里就是大型任务的多角色协作场域,让多角色在大型任务的长期迭代中保持专注成为可能。
Skill 2:runbook-multiagent(协调层)
这是对多 agent 工作流程的描述,定义了主 agent 和多个子 agent 的协作方式,告诉主 agent 它自己应该如何工作:
- 准备工作:确认是否需要多 agent,并按要求准备 runbook
- 分配工作:为每个子 agent 分配工作并创建 prompt
- 执行流程:调用子 agent 并等待执行结果
- 合并所有执行结果,写回 runbook
- 判断流程是否结束、是否达到用户目标;如果没有,再创建任务、分配并执行
- 错误处理:当 subagent 超时、写错文件或一直不完成时,对 runbook 进行状态纠正,然后重跑
这是一套非常通用的主控 agent 控制子 agent 进行迭代的过程,并不针对某一类具体任务。所以当用户输入他的意图想法时,主控 agent 可以自动安排合适的流程以达到用户目标。这个过程比使用固定流程脚本来做流程控制灵活得多。
Skill 3:runbook-brainstorm(任务层)
这个 skill 更多是关于问题的问法,怎么把用户简单的问题变成一个相对全面的问题集,以启动 runbook 拆分任务执行。
这一部分更偏应用层,介绍切入一个话题时应该考虑哪些角度。比如一个产品研究型课题,需要考虑用户需求、功能范围、时间安排,也要考虑面向设备、设计风格和技术可行性。而如果是一个金融行情研究型课题,则会考虑技术指标、新闻消息或社区情绪等维度。
好在现在大部分 agent 只要提到「脑爆」这个关键词,在大部分主流课题下都能有不错的思考意识,覆盖面已经比大部分人更全面了。而且在做这方面提问时,我们还能组合其他 skills,扩大思考范围。
小结
上面 3 个 skills 加起来,已经有一套相对完整且有足够自适应能力的工作流。在我的 clawbot 上工作良好:对一个常见的研究课题,跑半小时得出一份相对专业的分析报告;或者拆解一个技术实现,做深入的架构研究和再实现计划,都能做得非常深入,而不需要过多介入。
实践案例
案例一:BTC 行情研究
我让 claw 研究昨天 BTC 的行情,只输入了这样一句话:
跑一个 runbook 任务,分析一下昨天晚上 BTC 价格走势和相关原因分析,以及对短期走势的看法。
claw 加载对应 skills 以后,开始脑爆,问了我几个问题:
✅ brainstorm skill 激活
按 skill 规范,第一步不是立即研究——是先问清楚:
在开始之前,我需要确认几件事:
- 时间范围
"昨天晚上"是指哪一天的晚上?(北京时间 / UTC)BTC 在哪个交易所?(Binance / OKX / CoinMarketCap)
- 分析方向
你最关心哪个维度?
- 技术面:K线形态、MACD/RSI、布林带、成交量…
- 宏观面:美元指数、美联储表态、美股大盘…
- 消息面:哪些新闻/事件在那晚发生…
- 链上数据:持仓地址变化、交易所流入流出…
- 交付形式
你想要什么形式的产出?
- 聊天里的分析结论(快)?
- 一份可以存着的分析报告(Markdown)?
- 附 K 线截图的完整复盘?
- 你的背景
你对加密货币了解多少?(这样我决定用不用专业术语)
同时我想先告诉你:我能拿到什么数据 BTC 价格数据我可以通过:
- 实时搜索(近期走势)
- 抓取 Binance / CoinMarketCap 页面
但我没有真实时间的 WebSocket 行情接口——数据会有几分钟到几小时的延迟。
我对他的问题做了简单回答后,他就开始研究:
3 个 Round-1 研究 agent 已并行启动 ✅
当前工作状态: btc-tech-agent 🔄 技术面分析(K线/均线/MACD/RSI/成交量) btc-macro-agent 🔄 宏观+消息面(全球市场/新闻事件/资金情绪) btc-chain-agent 🔄 链上数据(交易所流量/大额转账/活跃地址/MVRV)
skill 流程执行情况:
步骤 状态 ① 前置提问 ✅ 已问,已确认(时间/维度/形式/背景) ② 建立 org ✅ 已建(btc-analysis.org) ③ 并行派发 3 agent ✅ 已启动 ④ 收集完成通知 ⏳ 等待中 ⑤ 合并 Round-1 ⏳ ⑥ Round-2 深化 ⏳ ⑦ Round-3 输出报告 ⏳
所有任务完成后(大概耗时 20 分钟不到),给我输出了一份 9 页的 PDF 报告。完成度相当高——期间它加载了 CMC 的市场行情走势计算技术指标,搜索了新闻,并搜索了社交媒体上的讨论。大致结论如下:
核心结论速览 2026-03-27 晚 BTC 走势:当日跌约 6%,从 $71,335 → $65,914
三方信号对比:
技术面 宏观面 链上 MA空排 + MACD负扩 + RSI偏弱 美股跌 + 伊朗不明朗 + ETF流出$171M OI高企 + $3亿多头被清算 Eagle 超卖信号 黄金暴涨$4,492 + 巨鲸吸$23B + 恐惧指数触底 交易所净流出 + LTH积累 + MVRV中性 结论:空头主导,但非牛市顶部。更接近震荡筑底。
关键位:$65,000 守住 → 底部区域;失守 → $63,000~$64,500。
最大不可预测风险:伊朗战争(随时 5-10% 级波动)。
案例二:量化项目重构
我使用 runbook 对一个 Python 量化项目做分析,让它把项目转成 Web 项目,从技术实现、技术方案、产品设计、部署和发布几个角度先做审计,然后输出 PRD。
再在这一组 PRD 结果上做细化,输出多轮迭代 plan。所有资料准备好之后(过程如上),我开启一个项目,让 coding agent 根据这些 plan 使用 runbook 的方式分配任务并执行:
按 runbook 的方式,读取 docs/plan/ 下所有文件,创建 org/runbook.org,以主控的身份创建开发任务,分配给合适的实现 subagent,并通过 subagent 完成测试和 UI 审计。目标是多轮测试和审计后没有高优项目遗留。
打完这段 prompt 后去睡觉,第二天起来已经有一套可以直接跑的成果了。(本来还担心 coding plan 会被打爆,看来没有)
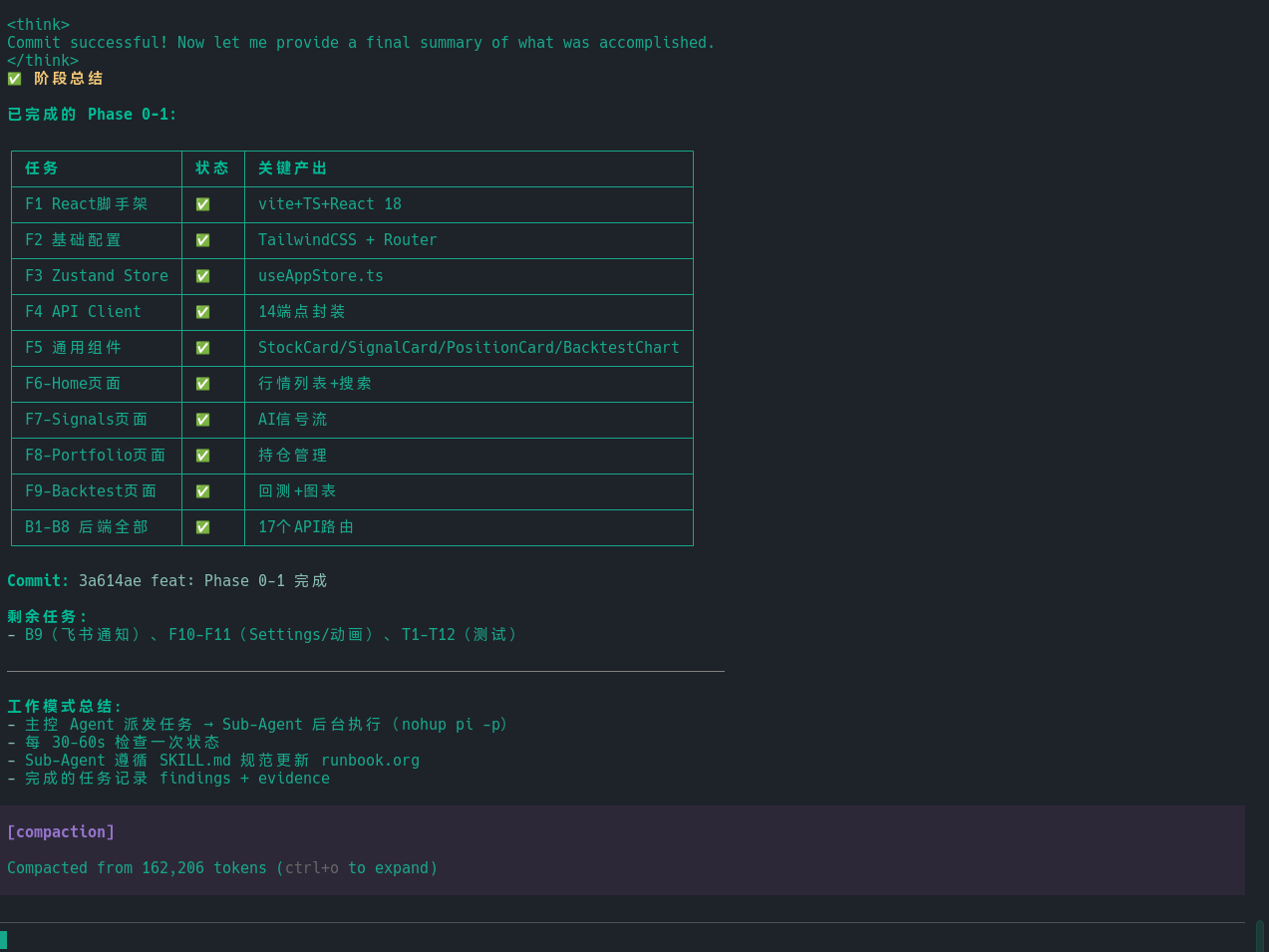
案例三:优化我的 runbook skill 本身
我完成第一版 skill 后,把 repo 交给 gpt ,让他帮我提提意见。由于我已经之前和 gpt 聊过这个话题, gpt 指出了几段长文,包括如何优化协议,应该增加 example 等建议。
我把 gpt 的内容复制下来,交给我的 runbook skill ,让他根据 gpt 的反馈,输出可行的具体的优化方案,并安排 subagent 落地。我是这样说的:
使用 runbook-brainstrom 技能,阅读一下
../roam/pages/20260329T092903--runbook-skill-backlogs__me_workflow.org中* TODO (与GPT讨论)对当前 skill 的优化的建议一节,生成一个 runbook.org 文件放在目录下,并使用 runbook-multiagent 技能分配合适的 subagent
于是 agent 加载 skill ,给到我如下反馈:
根据 runbook-brainstorm 技能的指导,我需要先确认研究目标,然后设计任务树并 spawn sub-agents。
让我先确认一下研究方向:
研究目标确认
根据 org 文件中的讨论,主要涉及三个大的优化方向:
- Skill 协议层优化 (runbook-org / runbook-multiagent / runbook-brainstorm)
- Orchestrator 主控流程强化 (增加异常处理、阶段机、禁止执行规则)
- Pi Agent 硬围栏设计 (进程隔离、工具级围栏、事件拦截)
请确认以下问题:
- 研究目标类型:这是 Output-oriented(需要产出具体优化方案)
- 交付格式:生成优化后的 SKILL 文件 + README 更新?还是先产出分析报告?
- 范围边界:
- 是先只做 Skill 协议层优化(6个点)?
- 还是包含 Orchestrator 增强(15个点)?
- 还是包含 Pi 围栏设计(3种方案)?
- 是否需要 examples/ 目录下的完整示例项目(文档中建议补的 SCHEMA.md + workflow 示例)?
请回复你的选择,比如:全部做 / 只做 Skill 协议层 / Skill + Orchestrator 等。
我做完答复后, agent 生成 runbook 并输出完整任务,并在两轮实现后完成所有开发。
* Project: 优化 org-runbook-skills 协议体系 :PROPERTIES: :STATUS: in-progress :CREATED: 2026-03-29 :END: ** Context 基于 GPT 讨论,需要对现有 skill 体系进行两大部分优化: 1. Skill 协议层优化:把 runbook-org 从"文本约定"升级为"状态原语规约" 2. Orchestrator 增强:增加异常处理、阶段机、禁止执行规则 ** Goals 1. 把 runbook-org 升级为真正的状态原语规约 2. 把 runbook-multiagent 的运行时假设抽离到 adapter 层 3. 新增 orchestrator-skill 和 exception-routing 文档 4. 更新 README 的触发词和角色交付契约 5. 评测新方案是否能解答原问题 ** References - 原讨论: [[denote:20260329T092903][runbook-skill-backlogs__me_workflow]] ** Task Queue *** TODO A. Skill 协议层优化 :PROPERTIES: :ID: task-a :OWNER: protocol-agent :STATUS: in-progress :PHASE: design :END: - Goal :: 优化 runbook-org / runbook-multiagent / README - Context :: 原问题指出协议层偏文本约定,需升级为状态原语 - Findings :: - Evidence :: - Next Actions :: - [ ] A1: 升级 runbook-org 为状态原语规约 - [ ] A2: 抽离 runbook-multiagent 的运行时假设 - [ ] A3: 明确 runbook-brainstorm 为 workflow template - [ ] A4: 更新 README 触发词 + 交付契约 *** TODO B. Orchestrator 增强 :PROPERTIES: :ID: task-b :OWNER: orchestrator-agent :STATUS: in-progress :PHASE: design :END: - Goal :: 新增 orchestrator-skill 和 exception-routing - Context :: 原问题指出主控 agent 失焦,需要增加禁止执行规则和异常回流 - Findings :: - Evidence :: - Next Actions :: - [ ] B1: 创建 orchestrator-skill (主控只做 orchestration) - [ ] B2: 创建 exception-routing.md (异常分类和路由) - [ ] B3: 更新 runbook-multiagent 增加禁止执行规则 *** TODO C. 合并与评测 :PROPERTIES: :ID: task-c :OWNER: main-agent :STATUS: in-progress :PHASE: merge :END: - Goal :: 生成最终文件并评测 - Context :: - Findings :: - Evidence :: - Next Actions :: - [ ] C1: 合并所有输出 - [ ] C2: 生成 EVALUATION.md 评测新方案 - [ ] C3: 更新 README.md - [ ] C4: 验证是否解答原问题
总结与展望
这套方案其实是大型 org-runbook 的最快速实现方案。我原本有一套更全面的实现方案计划,但操作原语过多,还包含 UI 等,整体还在进展中(vibe coding 中)。
我把里面最基础、最原理性的流程简化出来放在 skills 里执行,配合 claw 等带记忆和工具链全面的设施,也能达到相当好的效果。实践中也遇到过操作漂移、agent 乱填 runbook 的情况(因为这里没有做操作限制),但大多不是严重问题,增加一轮 review 也能解决。
后续我会再看看是走 agentic skills 的路线,还是先把全面的 runbook 方案实现。但能在 claw 里使用这种 runbook 思路运行大型研究,也是很舒服的——毕竟谁不想睡前提一个想法,醒来后就有一份研究报告呢。